messaging based Intelligent Processing Unit (m-IPU)
m-IPU is a new computing technology for AI/HPC needs. It is a well-known fact that custom Application-Specific Integrated Circuits (ASICs) can provide more benefits (area, power, performance) compared to the generic CPUs for specific applications. The CPUs (GPUs likewise, which is a variant of CPU with Single Instruction Multiple Data architecture) would spend the majority of time fetching instruction and operand data from memory which are molded to run on the generic hardware, and hence are slower. However, it is impossible to have a custom design for every possible application. Instead, our disruptive idea is to have a chip that can be reconfigured at run-time to behave as a custom-ASIC for each running AI applications to deliver the best performance. It revolves around a unique flexible virtual interconnection scheme where any computing core can be connected to another at run-time.
Seemless dataflow from left to right without requiring load/store like memory accesses for intermediate data storage and loads. A VGGNET implementation is shown. Once programmed, the communication between layers do not require centralized memory access or FPGA like routing.
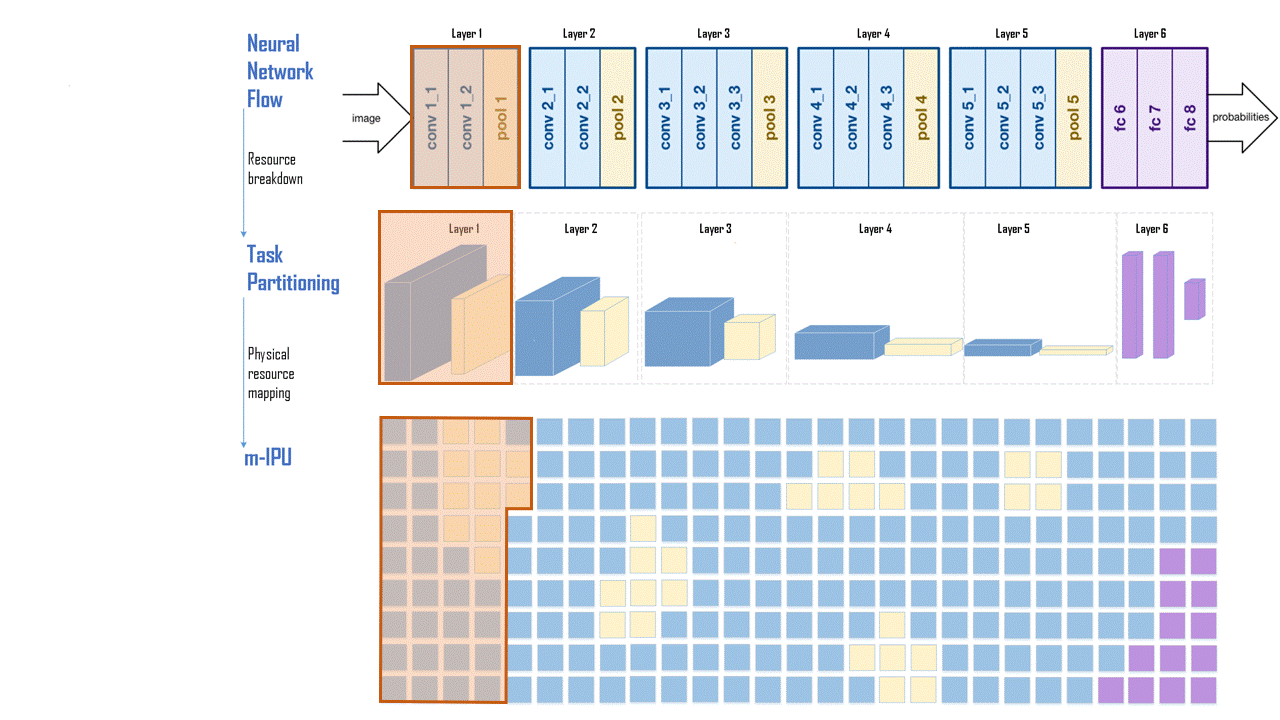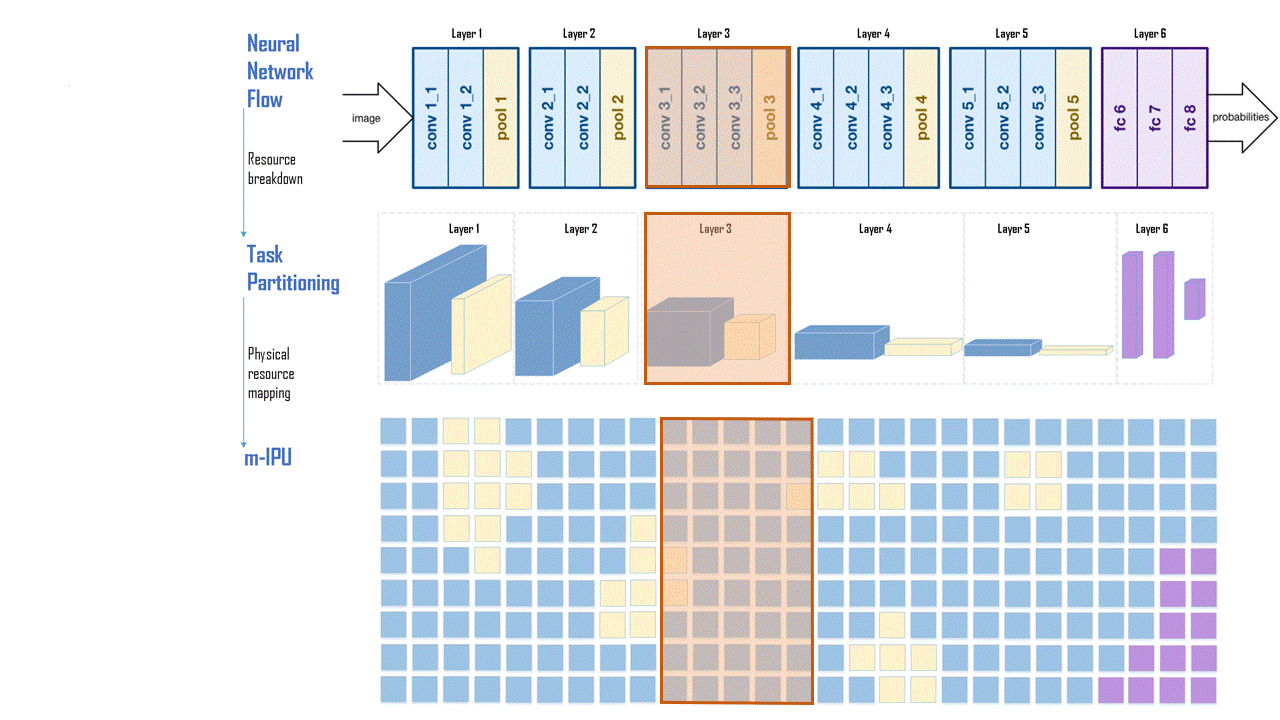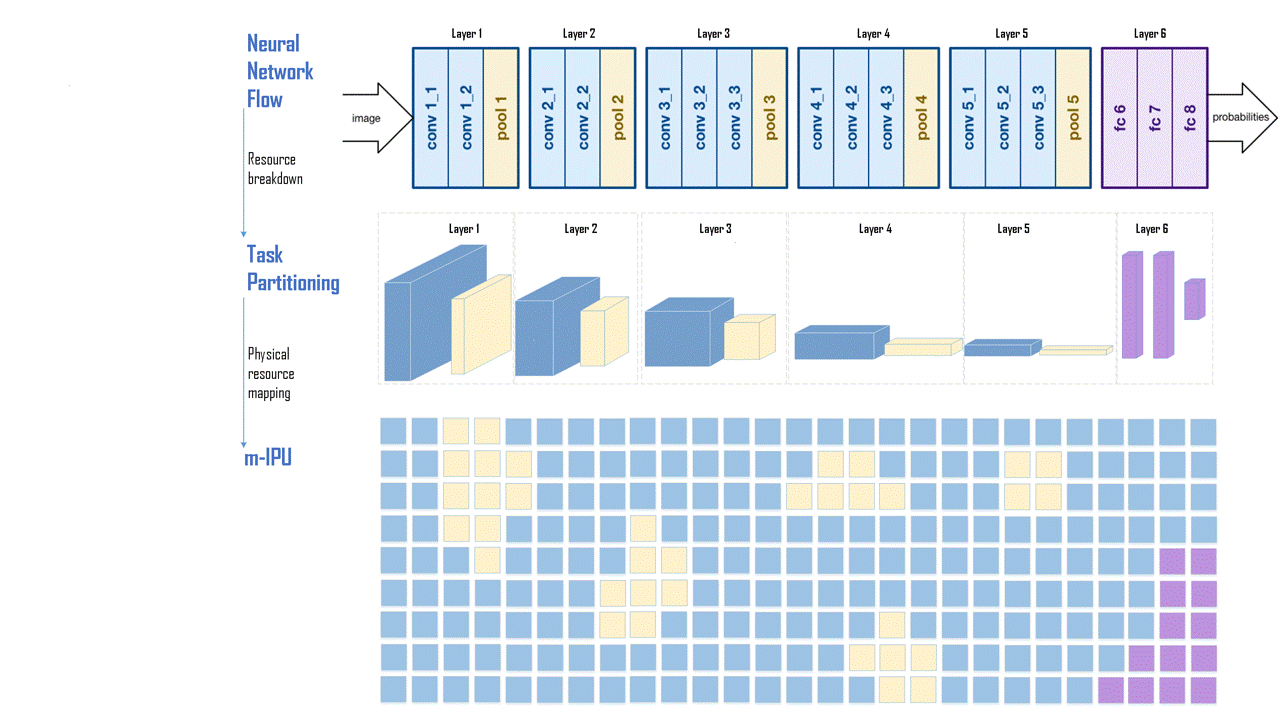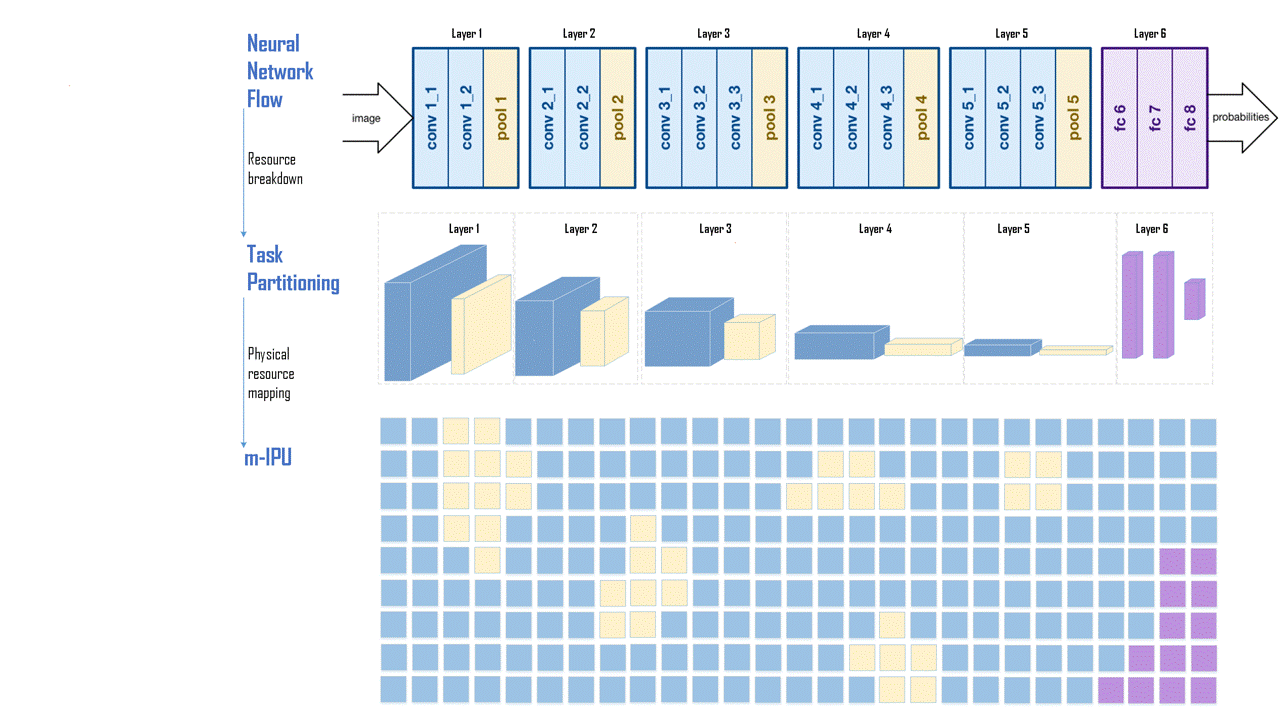
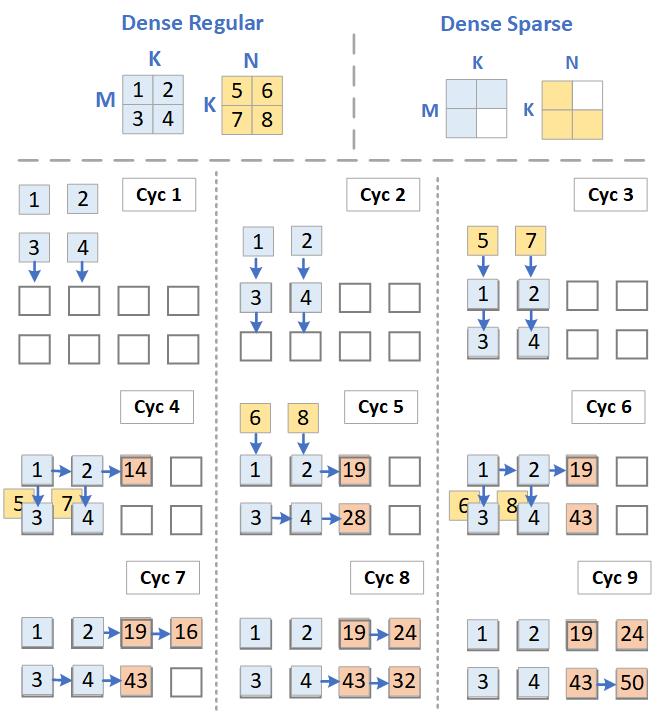
Efficient implementation of matrix operations. Once programmed, the computing blocks can communicate among themselves and operate on the incoming data. Both dense and sparse data can be mapped without any loss in resource utilization. A wide range of data can be mapped for a variety of applications including Deep Neural Networks, Genomic/Big Data Search, Page Rank, Sorting, etc. Since the computation and memory elements are distributed across the chip, the requirements cache memory bandwidth is significantly less.
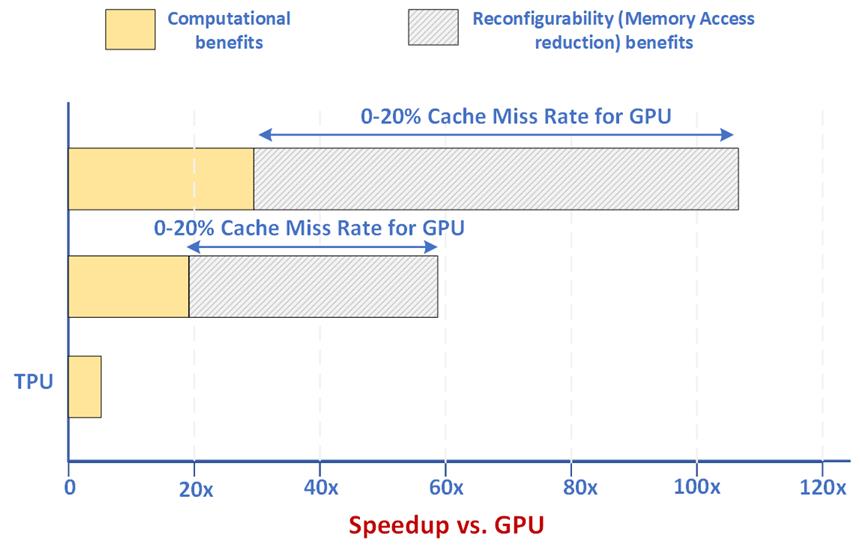
Significant gains with respect to TPU and GPU architectures are predicted. The benefits stem from efficient utilization of computing cores and reduced reliance on memory for data fetch and storage.